TL;DR
In LLM RL post-training, every optimizer step on the trainer has to push fresh weights into the inference engine doing rollouts. Under a disaggregated training/inference architecture, this has long been treated as a problem that demands high-bandwidth RDMA — sync cost scales linearly with model size and tends to dominate the sync phase.
In the first half of 2026, three independent threads — academic, industrial, and open-source — converged on the same observation: after one RL step, only ~1% of the weights actually change; in BF16, more than 99% of elements are byte-identical to the previous step. Sending only the changes (the delta) cuts the wire traffic by roughly two orders of magnitude, losslessly and bit-identically. The bottleneck is no longer hardware (high-bandwidth interconnect) but software (how to encode the sparse delta) — RL training can now run over plain Ethernet, and even across data centers backed by shared storage.
This post walks through where that observation came from, who shipped it, and then uses slime as a concrete example to dissect exactly what has to change in a system to do delta weight sync.
1. Why weight sync is a bottleneck
Modern RL frameworks generally split the trainer (Megatron / FSDP) from the rollout/inference engine (SGLang / vLLM): the two use different parallelism strategies, different kernels, and often live in different processes, nodes, or even data centers. That setup leaves one unavoidable step: after every policy update, the trainer must push its new weights to the inference engine, otherwise rollouts are sampled from a stale policy.
The default approach is full broadcast: send every parameter from the trainer to every inference rank (typically the trainer’s rank 0 and the inference engine’s ranks form a single NCCL group). Its cost grows linearly with model size and tends to dominate the sync phase in disaggregated setups.
The community’s first instinct was to make the transfer faster, not to transfer less. For example, the slime team brought full-sync latency down from ~60s to ~7s via async tensor gathering, bucketing (reducing ~2000 HTTP calls to ~120), tensor flattening, and weight-loading caches (see Biao He’s blog). But fundamentally these still move every parameter.
Once the network drops from RDMA to commodity Ethernet (a few hundred MB/s), full broadcast is no longer viable. As the SparseRL-Sync paper (arXiv 2605.07330) notes in its intro, existing RL systems (OpenRLHF, veRL, StreamRL, …) optimize rollout throughput while implicitly relying on a high-bandwidth intra-cluster fabric; ported to commodity networks, full broadcast achieves such low effective throughput that syncing a mere 8B model takes more than 100 seconds. Larger models, or anything that crosses a region boundary, push full broadcast outside engineering feasibility.
2. The observation: RL weight updates are inherently sparse
The turning point came when PULSE (arXiv 2602.03839, Erfan Miahi @ Covenant AI and Eugene Belilovsky @ Mila) gave the phenomenon a systematic treatment. The core claim:
At the learning rates typical of RL post-training, many Adam updates are small enough to vanish when cast back to BF16 — they fall under the BF16 rounding threshold at the current weight’s magnitude. So after one step, the vast majority of weight elements have identical byte representations to the previous step.
PULSE calls this compute-visible sparsity and reports about 99% of per-step updates are invisible after the BF16 cast. Independent work has produced strikingly consistent measurements:
- SparrowRL (arXiv 2602.11456) reports about 1% of parameter elements change per step;
- Fireworks (Frontier RL Is Cheaper Than You Think) reports >98% of bf16 weights are bit-equivalent between adjacent checkpoints, with the average delta running about 1.98% of the full model;
- slime’s documentation (delta-weight-sync.md) takes ~3% density as the typical operating point, yielding ~5 GB of delta on a 355B model.
If that’s the case, there’s no reason to send the whole model every step. It suffices to ship the indices of the changed positions plus the new values, and let the receiver overwrite those slots. Because every element is overwritten with the trainer’s exact bytes — no arithmetic involved — the procedure is lossless / bit-identical. There is no floating-point drift to worry about, as there would be with an additive delta. Communication scales roughly with density: ~1–3% density means roughly two orders of magnitude less bandwidth.
3. Three threads converged independently in four months
The idea was operationalized almost simultaneously by multiple groups in the first half of 2026, along a strikingly clean timeline.
Academic / papers (from February)
- PULSE / PULSESync — arXiv 2602.03839. Introduces compute-visible sparsification; ships lossless sparse BF16 weight patches from trainer to inference workers; reports a >100× communication reduction, bit-identical reconstruction, and robustness to transmission errors.
- SparrowRL — arXiv 2602.11456 (“RL over Commodity Networks”). Sparse delta checkpoints plus multi-stream transmission, pipelined with rollout generation. Reports 79× payload reduction per step on Qwen3-8B, 2.4–9.5× higher throughput than full broadcast over WAN, and 1.21–1.59× higher tokens/$ than reserved RDMA clusters.
- SparseRL-Sync — arXiv 2605.07330, backing the Helix framework (Scitix, Megatron + SGLang). Reports >99% element-level sparsity, transmits indices and values, 100% fidelity, ~100× reduction.
Industrial systems (from March)
- Fireworks — Frontier RL Is Cheaper Than You Think (Mar 23). In a disaggregated rollout/training setup, deltas relative to the previous checkpoint update a cross-region rollout fleet. In their sample 1024 GiB model, the average delta is 20.3 GiB (1.98%), shrinking cross-region transfer volume by about 94% compared to moving the full model every time.
- Cursor — Composer 2 Technical Report. Training and inference live in different regions; every training step uploads a delta-compressed weight update to a shared S3 bucket, sharded across training ranks. The system also supports mid-trajectory weight refresh — later tokens in the same sequence can be generated by a newer checkpoint than earlier tokens.
Open source (from May)
- Hugging Face TRL — Shipping a Trillion Parameters With a Hub Bucket: Delta Weight Sync in TRL (May 27). The trainer diffs BF16 weights before and after each optimizer step, stores changed elements as a sparse safetensors file, uploads to a HF (Xet) Bucket, and has vLLM pull and apply it. Reports per-step payload dropping from 1.2 GB to 20–35 MB on Qwen3-0.6B; the demo is fully disaggregated, with weights flowing through a single Hub bucket — no RDMA, no VPN.
- slime (THUDM) — the worked example dissected in the next section.
Engine layer (in progress)
- vLLM’s RFC #31848 (Native Weight Syncing APIs) and issue #39451 (sparse in-place weight updates) propose first-class engine support for “receive only changed (index, value) pairs and apply in place,” cutting transfer from O(numel) to O(nnz) and removing the need for a user-maintained CPU snapshot.
The table below summarizes the engineering choices each system made (data sourced from the links above):
| System | Transport | Encoding | Diff baseline | Lossless | Reported compression |
|---|---|---|---|---|---|
| PULSE | NCCL | sparse BF16 patch | step-over-step | yes | 100×+ |
| SparrowRL | multi-stream / commodity net | sparse delta | step-over-step | yes | 79× (Qwen3-8B payload) |
| Fireworks / Cursor | cross-region S3 | compressed delta | adjacent checkpoints | — | ~94% transfer reduction (1.98% delta) |
| TRL | HF Hub Bucket (Xet) | sparse safetensors | step-over-step | yes | 1.2GB → 20–35MB (Qwen3-0.6B) |
| slime | NCCL or disk / shared FS | indices / deltas / deltas_zstd | pinned-CPU snapshot | yes | ~3% density (~5 GB on 355B) |
Three dimensions account for most of the divergence: transport medium (NCCL / object store / shared FS), how the positions are encoded, and what the diff is taken against. The next section uses slime to make each of these concrete.
4. A detailed look at slime’s delta weight sync
slime (THUDM’s RL post-training framework, Megatron + SGLang) ships a clean, readable implementation documented in delta-weight-sync.md. It is a good specimen for understanding exactly what changes are required to land delta sync. The analysis below is grounded in slime’s main-branch source and docs.
4.0 Where the changes land
slime’s delta implementation is tightly scoped, but it carries one easily-overlooked structural fact: the sender and the receiver must each change, and the receiver changes live in the inference engine.
Sender (inside slime, all new for delta):
- A new file,
slime/backends/megatron_utils/update_weight/update_weight_from_distributed_delta.py(~860 lines), definesclass UpdateWeightFromDistributedDelta(UpdateWeightFromDistributed)— a subclass of the existing full-sync class (~386 lines). It reuses the parent’s NCCL group setup, TP/EP gather, and HF format conversion, overriding onlyupdate_weights,connect_rollout_engines, and the send logic. - New runtime state: a pinned-CPU full snapshot of the weights. This is the largest single resource addition over full-sync.
DeltaStateallocatestorch.empty_like(tensor, device="cpu", pin_memory=True)for every HF tensor that has been broadcast. The snapshot is full-coverage — each PP-source rank holds its share of HF tensors, and the aggregate is roughly one complete model resident in pinned host memory. It is seeded on the firstupdate_weightscall (a single full pass over parameters; the docs report ~50 s blocking init on a 355B model), and every subsequent diff is taken against it. This is purely additive memory cost: full broadcast keeps no snapshot. - Dispatch: about 15 lines in
actor.py—if update_weight_mode == "delta": cls = UpdateWeightFromDistributedDelta, with a lazy import so old images are unaffected. - Args: a
--update-weight-{mode,transport,encoding,disk-dir,buffer-size}family inarguments.pyplus their validation rules.
Receiver (inside the engine, not in slime):
The code that actually writes the sparse delta back into the model weights lives in SGLang, contributed via a separate PR: sgl-project/sglang#26519 “Add delta weight update receiver” (~339 added lines, of which ~280 are in model_executor/model_runner.py). slime’s sglang.py is just a ~43-line shim that re-exports DeltaEncoding / DeltaParam / DeltaSpec from sglang.srt.managers.io_struct. As of this writing, that PR is still open and conflicting, not yet merged into SGLang main — running slime delta sync therefore requires a custom / patched SGLang build that carries the receiver (slime’s own source comments note that older sglang images do not contain the delta-sync io_struct).
The first takeaway, then: delta weight sync is not a purely framework-side feature. The sender framework needs to encode a sparse delta; the receiver engine needs to apply one. Both are required, and today the receiver side still depends on an unmerged SGLang PR.
4.1 Sender pipeline (runs only on the PP-source rank)
The diagram below summarizes the data flow of one sync; the four steps follow.
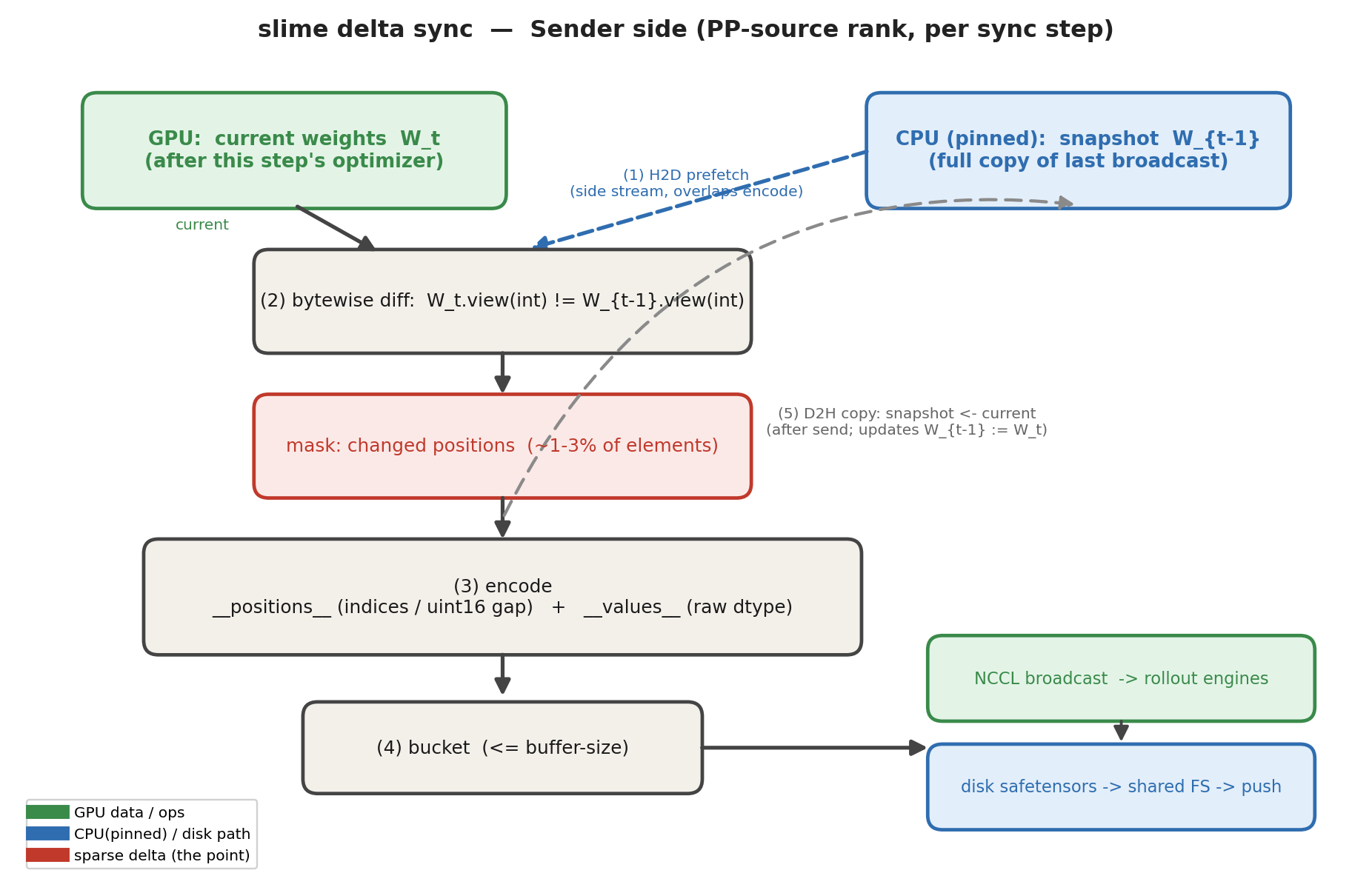
slime delta sync sender pipeline (PP-source rank): the current GPU weights W_t and the CPU-pinned full snapshot W_{t-1} feed a bytewise diff, producing a sparse mask (~1–3% of elements); the changes are encoded into __positions__ + __values__ and bucketed, then flushed via NCCL broadcast or disk safetensors; after the send, a side-stream D2H copy refreshes the snapshot so that W_{t-1} := W_t for the next step.
Each sync runs four steps:
-
Diff. Compare the current weights against the pinned-CPU snapshot bytewise —
current.view(int_dtype) != snapshot.view(int_dtype). Reinterpreting the storage as integers makes the comparison dtype-agnostic, arithmetic-free, and lossless. -
Encode. Pack changed
(position, value)pairs into a__positions__byte blob, a__values__tensor, and a per-parameter manifest. The three encodings only decide how positions are packed; values are always sent verbatim in the parameter’s dtype:Encoding Position representation Where it fits indicesint32 absolute positions (4 B / nnz) NCCL or fast intra-cluster FS (≥ ~600 MB/s) deltasuint16 gap-deltas with uint32 fallback (~2 B / nnz at 2% density) medium-bandwidth FS (~300–500 MB/s) deltas_zstddeltaswrapped in zstd L1cross-DC / cross-region shared FS (≤ ~300 MB/s) Why gap encoding shrinks positions:
mask.nonzero()produces positions in ascending order, the expected gap between consecutive non-zeros is1/p, and at p = 2% the probability ofgap > 65535is essentially zero. So uint16 suffices (uint32 is kept as a per-param fallback) and the positions blob is halved. -
Bucket and flush. A bucket accumulates encoded chunks until
--update-weight-buffer-sizebytes, then flushes. It is worth being explicit that the two halves of the bucket live in different places: positions have already been turned into host-sidebytesat encode time (viapositions.cpu().numpy().tobytes()— they are small and need to be byte-packed for the wire anyway), while values stay as a GPU tensor (they are the bulk of the payload, so a premature D2H is wasteful). At flush time each transport completes the missing leg: the NCCL transport pushes positions back to the GPU with a single H2D and broadcasts both tensors from device memory; the disk transport pulls values back to the CPU and hands the pair to a background thread that writes one safetensors file (I/O and optional zstd compression happen off the critical path). -
Snapshot. A D2H copy on a side stream updates the snapshot with the values just sent, overlapping with the next chunk’s encode.
A few pipeline tricks are worth calling out:
- One-step H2D snapshot prefetch lookahead — chunk N+1’s snapshot transfer overlaps chunk N’s compute+encode.
- The expert pass is split into four sub-passes, so that the receiver’s apply for an earlier batch overlaps with later experts being encoded rather than piling up at the end of sync.
- Checksum —
torch.hash_tensor(XOR-reduce over a uint64 bitcast) is computed before the flush and re-verified on the receiver, catching wire corruption between encode and apply.
4.2 Receiver: NaN-masked overwrite (in SGLang)
The details below come from the SGLang PR (#26519). Both transports — disk file or distributed NCCL broadcast — funnel into the same _apply_delta_payload(encoding, params, positions, values, expected_checksum). The overall flow is shown below; the rest of this section unpacks it.
![slime delta sync receiver apply, inside SGLang (sgl PR #26519): the sparse payload lands on the GPU; the checksum is re-verified; each parameter is decoded by densifying back into a full-shape NaN tensor (sparse on the wire, dense on apply — chunked to 512 MB by --update-weight-delta-chunk-bytes); SGLang’s native model.load_weights is reused, wrapped by _delta_apply_context which monkeypatches Tensor.copy_ to perform dst[~isnan(src)] = src — an in-place masked overwrite onto the existing GPU weight W. A data_ptr range index decides whether a copy target is actually a model parameter.](delta-receiver-apply.png)
slime delta sync receiver apply, inside SGLang (sgl PR #26519): the sparse payload lands on the GPU; the checksum is re-verified; each parameter is decoded by densifying back into a full-shape NaN tensor (sparse on the wire, dense on apply — chunked to 512 MB by --update-weight-delta-chunk-bytes); SGLang’s native model.load_weights is reused, wrapped by _delta_apply_context which monkeypatches Tensor.copy_ to perform dst[~isnan(src)] = src — an in-place masked overwrite onto the existing GPU weight W. A data_ptr range index decides whether a copy target is actually a model parameter.
Verify first, then apply. The receiver recomputes torch.hash_tensor over positions and values, and refuses to apply if the result disagrees with the sender’s checksum — intercepting any corruption between encode and apply.
Per-parameter decode densifies back to a full-shape tensor, on the GPU. _decode_delta_one_param allocates a fresh full-shape buffer with torch.full((numel,), nan, dtype=param_dtype, device=self.device) — self.device is the GPU; positions and values are first moved to device with .to(self.device). The position blob is unpacked on the GPU with bit-shifts (the gap encoding is inverted by idx = (unpacked + 1).cumsum() - 1), then flat.index_copy_(0, idx, values) writes the changed values into the right slots, leaving the rest as NaN.
Note an easily missed cost: the wire is sparse, but the apply re-densifies — each parameter requires a transient full-shape GPU allocation as the source. To bound peak VRAM, the PR batches multiple parameters into chunks capped by
--update-weight-delta-chunk-bytes(default 512 MB) before invokingload_weights; the disk path also provides--update-weight-delta-read-workers(default 4) for parallel file reads. (Eliminating this densification and the sender’s CPU snapshot is precisely what vLLM RFC #39451 is after with a true sparse in-place API.)
Application is in-place, on the existing GPU weight, by monkeypatching around the model’s native load_weights. The decoded full-shape NaN tensor is fed into the model’s native model.load_weights(chunk). The trick lives in _delta_apply_context, a context manager that, on entry, replaces the process-level torch.Tensor.copy_ and torch.Tensor.fill_ with patched versions, restoring the originals on exit. The patched copy_ performs mask = ~isnan(src); dst[mask] = src[mask] — overwriting only the changed positions, directly on the existing GPU weight (in place), without allocating a new weight tensor; unchanged positions retain their previous values.
How does copy_ know whether a given destination is a model parameter? _param_storage_index precomputes a data_ptr range index over every parameter/buffer; the patched copy_ uses bisect to test whether the destination tensor’s pointer falls inside any known parameter’s storage. If yes, the NaN-masked branch fires; otherwise the original copy_ runs (so sliced or viewed weights still match, while transient scratch buffers are left alone). post_load_weights (fp8 scale, MoE bias, etc.) is wrapped in a layer that temporarily restores the originals, so post-processing keeps its usual semantics.
Why this is lossless and drift-free. The receiver only ever writes the trainer’s exact bytes at changed positions — no arithmetic, no w += delta. So the apply is bit-identical by construction, and there is no per-step floating-point drift to accumulate. That is the fundamental difference from additive-delta designs: no periodic full re-sync is needed to keep the receiver from drifting.
4.3 How invasive is the change?
- Light touch on the training side. Pure subclassing plus new arguments. Loss, optimizer, and the existing full-sync path are untouched, and default behavior is unchanged (~860 lines, all in one new file).
- One tangible resource cost. The pinned-CPU full snapshot effectively keeps a complete model resident in host memory, and the initial seed blocks for ~50 s on a 355B model. The trade is “extra host memory and a one-time init cost in exchange for cheaper per-step communication.”
- Hard dependency on the engine, currently unmerged. A delta-receiver-capable SGLang build is required (PR #26519, ~339 lines). The PR is still open and conflicting at the time of writing, so any deployment needs to cherry-pick or patch — this is the most concrete adoption gate today.
- One explicit restriction.
delta + colocateis rejected at argparse. Colocate uses CUDA IPC, where only a ~64 B memory handle crosses processes; delta has no bytes to save and only adds the snapshot/diff/encode overhead.
4.4 Does it compose with RDMA?
Yes — and the two concerns are orthogonal. slime decomposes sync into two independent axes:
- What to send —
mode:fullordelta - How to send it —
transport:ncclordisk
| mode | transport | behavior |
|---|---|---|
full |
nccl |
default: broadcast every HF weight chunk over a trainer↔engine NCCL group |
full |
disk |
write a complete HF checkpoint, then have the engine update_weights_from_disk |
delta |
nccl |
broadcast sparse changed positions and values over NCCL |
delta |
disk |
write sparse safetensors to a shared FS, then push to the engine to apply |
The key observation is:
delta + ncclis “delta over NCCL”. NCCL still runs on top of IB / RoCE — i.e., an RDMA fabric. So you simultaneously get RDMA’s high bandwidth and a ~1–3% wire payload; the two optimizations stack rather than conflict. slime’s docs position the NCCL transport as an intra-datacenter validation baseline that exercises the wire encoding and apply logic.delta + disk(shared FS / object storage) targets cross-DC / cross-region setups without RDMA. Full broadcast is not viable there, but a sparse delta (~3% density, ~5 GB for a 355B model) is reasonable over a few-hundred-MB/s shared FS.
So delta is not a replacement for RDMA; it is “further savings when RDMA is available, and a path to disaggregated RL when it isn’t.”
4.5 Configuration
Cross-datacenter (the primary use case, disk transport):
--update-weight-mode delta
--update-weight-transport disk
--update-weight-encoding deltas_zstd # best for shared FS ≤ ~300 MB/s
--update-weight-disk-dir /shared/fs/delta-updates
Intra-cluster validation baseline (NCCL transport):
--update-weight-mode delta
--update-weight-transport nccl
--update-weight-encoding indices # cheapest compute, no compression
5. The engine layer is moving toward first-class support
The walkthrough above makes a structural point clear: the apply lives in the engine, and today every framework is essentially patching its engine of choice. vLLM’s RFC #31848 and issue #39451 are pushing to make “sparse in-place weight update” a first-class engine API — receive (indices, values), apply in place, drop transfer cost from O(numel) to O(nnz), and lift the user’s burden of maintaining a CPU snapshot.
This is the path from “each framework hacks its engine” to “engines treat sparse delta as a standard capability.” Once the engine-side API stabilizes, framework-side adoption cost should fall significantly.
6. Closing thoughts
A blunt observation — that an RL step changes almost none of the weights — has reshaped the cost structure of RL training in a matter of months: trainer and rollout can now sit on commodity networks, and even across regions, with tokens-per-dollar that can outperform reserved RDMA clusters (per SparrowRL).
A few open questions worth tracking:
- Could a more aggressive lossy delta (e.g., discarding the smallest changes) compress further without hurting convergence?
- In long training runs, what is the drift envelope under an additive scheme (slime sidesteps this entirely with pure overwrite)?
- Under MoE routing, does the sparsity story still hold per-expert? Do uneven activation frequencies make the delta distribution lopsided in ways that need new bookkeeping?
These look like natural next steps.
References
- PULSE / PULSESync, arXiv 2602.03839
- SparrowRL (“RL over Commodity Networks”), arXiv 2602.11456
- SparseRL-Sync (Helix), arXiv 2605.07330
- Fireworks, “Frontier RL Is Cheaper Than You Think”
- Cursor, Composer 2 Technical Report
- Hugging Face TRL, “Shipping a Trillion Parameters With a Hub Bucket: Delta Weight Sync in TRL”
- slime, docs/en/advanced/delta-weight-sync.md; SGLang receiver in sgl-project/sglang#26519
- vLLM issues #31848, #39451
- Biao He, “Optimizing Weight Sync in slime”