TL;DR
In LLM RL post-training, every optimizer step on the trainer has to push fresh weights into the inference engine doing rollouts. Under a disaggregated training/inference architecture, this has long been treated as a problem that demands high-bandwidth RDMA — sync cost scales linearly with model size and tends to dominate the sync phase.
In the first half of 2026, three independent threads — academic, industrial, and open-source — converged on the same observation: after one RL step, only a small fraction of the weights actually change; in BF16, more than 99% of elements are byte-identical to the previous step. Sending only the changes (the delta) cuts wire traffic by roughly two orders of magnitude, losslessly and bit-identically. The bottleneck shifts from hardware (a high-bandwidth interconnect) to software (how to encode the sparse delta) — RL training can now run over plain Ethernet, and even across data centers backed by shared storage.
This post walks through where that observation came from, who shipped it, and then uses slime as a concrete example to dissect exactly what has to change in a system to do delta weight sync.
1. Why weight sync is a bottleneck
Modern RL frameworks decouple the trainer (Megatron / FSDP) from the rollout/inference engine (SGLang / vLLM): the two use different parallelism strategies and operator implementations, and often run in different processes, nodes, or even data centers. That creates an unavoidable step: after every policy update, the trainer’s new weights must be synced to the inference engine, or sampling runs on a stale policy.
The default is full broadcast: ship all parameters from the trainer to every inference rank (typically the trainer’s rank 0 and all inference ranks form one NCCL group). Its cost grows linearly with model size and usually dominates the sync phase in a disaggregated setup.
The community’s early optimization was “move it faster,” not “move less.” slime, for instance, brought full-sync latency from ~60s down to ~7s — via async tensor gathering, bucketing (~2000 HTTP calls down to ~120), tensor flattening, and weight-loading caches (see Biao He’s blog). But that still transfers the full weights.
Once the network degrades from RDMA to ordinary commodity networking (hundreds of MB/s), full broadcast stops being viable. The SparseRL-Sync paper (arXiv 2605.07330) notes that existing RL systems (OpenRLHF, veRL, StreamRL, …) mostly assume intra-cluster high-bandwidth networks; move to a commodity network and full broadcast’s effective throughput is low enough that syncing an 8B model takes over 100 seconds. At larger scale and across regions, full broadcast is simply not practical.
2. The observation: RL weight updates are inherently sparse
The turning point is PULSE’s (arXiv 2602.03839; Erfan Miahi @Covenant AI, Eugene Belilovsky @Mila) systematic analysis of the phenomenon. Its core claim:
At typical RL post-training learning rates, many of Adam’s updates are too small to be visible after casting back to BF16 — the update falls below the BF16 rounding threshold of the current weight value. So after one step, the byte representation of the vast majority of weight elements is unchanged.
PULSE calls this compute-visible sparsity and reports ~99% of per-step updates are invisible after the BF16 cast. Other independent work measured the same thing:
- SparrowRL (arXiv 2602.11456) reports ~1% of parameter elements change per step;
- Fireworks (Frontier RL Is Cheaper Than You Think) reports >98% of bf16 weights are bit-equivalent between adjacent checkpoints, with an average delta of ~1.98% of the full size;
- slime’s docs (delta-weight-sync.md) take ~3% density as a typical operating point — about 5GB of delta for a 355B model.
Given that, there’s no need to ship the full weights every step: just send the indices and new values of the changed positions, and have the receiver overwrite those positions. Because it’s element-wise overwrite of the trainer’s exact bytes, there’s no arithmetic involved — so it’s lossless and bit-identical, and free of the floating-point accumulation drift that additive-delta schemes suffer. Traffic scales roughly with density: ~1–3% density buys ~two orders of magnitude less wire traffic.
3. Three threads converged independently in four months
The same idea was shipped near-simultaneously and independently by academia, industry, and open-source in early 2026. The core recipe is essentially the same everywhere — send a sparse delta, reconstruct losslessly, tens-to-hundreds× compression (numbers in the table below) — so the real difference is the angle each one came in from:
Academia / papers (from February)
- PULSE / PULSESync (arXiv 2602.03839) framed it first: introduced compute-visible sparsification and showed the sparse BF16 patch reconstructs bit-identically and is robust to transmission errors.
- SparrowRL (arXiv 2602.11456) pulled the target network off RDMA onto plain Ethernet / WAN: multi-stream transfer overlapped with rollout generation, arguing this works on commodity networks — with tokens/$ even beating a reserved RDMA cluster.
- SparseRL-Sync / Helix (arXiv 2605.07330; Scitix, Megatron + SGLang) gives the most extreme sparsity evidence: element-level sparsity over 99%.
Industrial systems (from March)
- Fireworks (Frontier RL Is Cheaper Than You Think, 3-23) put it into production: decoupled rollout/training, cross-region updates, with the diff baselined against the adjacent checkpoint rather than the more common “before/after a step.”
- Cursor (Composer 2 technical report) adds one distinctive capability: mid-trajectory updates — later tokens in a sequence can be generated by a fresher checkpoint than earlier ones.
Open-source frameworks (from May)
- Hugging Face TRL (Delta Weight Sync in TRL, 5-27) made the transport as light as possible: weights flow through a single HF Hub bucket, fully decoupled, with no RDMA or VPN.
- slime (THUDM) is the worked example we dissect in the next section.
The engine layer is catching up too: vLLM has landed sparse in-place weight update as a native capability (#40096, merged 2026-06; currently NCCL-only, TP=PP=1).
The table summarizes each design’s engineering trade-offs (sources are the links above):
| Implementation | Transport | Encoding | Diff baseline | Lossless | Reported compression |
|---|---|---|---|---|---|
| PULSE | NCCL | sparse BF16 patch | step before/after | yes | 100×+ |
| SparrowRL | multi-stream / commodity net | sparse delta | step before/after | yes | 79× (Qwen3-8B payload) |
| Fireworks / Cursor | cross-region object store (S3) | compressed delta | adjacent ckpt | — | ~94% traffic cut (1.98% delta) |
| TRL | HF Hub Bucket (Xet) | sparse safetensors | step before/after | yes | 1.2GB→20–35MB (Qwen3-0.6B) |
| slime | NCCL or disk/shared FS | indices / deltas / deltas_zstd | pinned-CPU snapshot | yes | ~3% density (355B ≈ 5GB) |
The divergence is mostly along three axes: transport (NCCL / object store / shared FS), how positions are encoded, and the diff baseline. slime makes all three concrete — let’s dig in.
4. A detailed look at slime’s delta weight sync
slime (THUDM’s RL post-training framework, Megatron + SGLang) gives a complete and readable implementation in its docs (delta-weight-sync.md), making it a good reference specimen for “what has to change to land delta sync.” The analysis below is based on slime’s main-branch source and docs.
4.0 Where the changes land
To land delta sync, the changes split across two ends, with one easily-missed key point: both the sender and the receiver have to change, and the receiver change lives inside the engine, not in slime.
- Sender (inside the slime framework): a new subclass of the full-sync class, reusing the parent’s NCCL group, TP/EP gather, and HF-format conversion, and overriding only the diff / encode / send steps. The one genuinely new resource is a host-resident pinned-CPU full-weight snapshot, used as the baseline for each step’s bytewise diff. That snapshot is the only net-new cost relative to full broadcast (which needs no snapshot), and it has to be seeded once at startup with a full pass over the params (slime’s docs note ~50s on a 355B model). Everything else is the mode selection at the entry point plus a set of new
--update-weight-*flags. - Receiver (inside the engine, not in slime): the logic that actually writes the sparse delta back into the weights lives in SGLang, supplied by a separate PR (sgl-project/sglang#26519); slime only carries a thin shim that imports its data structures. Worth noting: to run slime delta sync you need a SGLang build that includes this receiver — until the PR lands upstream, bring your own.
So the first takeaway is: delta weight sync isn’t a pure framework feature. The sending framework must be able to encode the sparse delta, and the receiving engine must be able to apply it — neither alone is enough; the latter is provided on the SGLang side, so pair it with the matching build.
The rest splits into the two ends: the sender (§4.1) and the receiver (§4.2).
4.1 Sender pipeline (runs only on the PP-source rank)
The figure below summarizes one sync’s data flow on the sender; the steps follow.
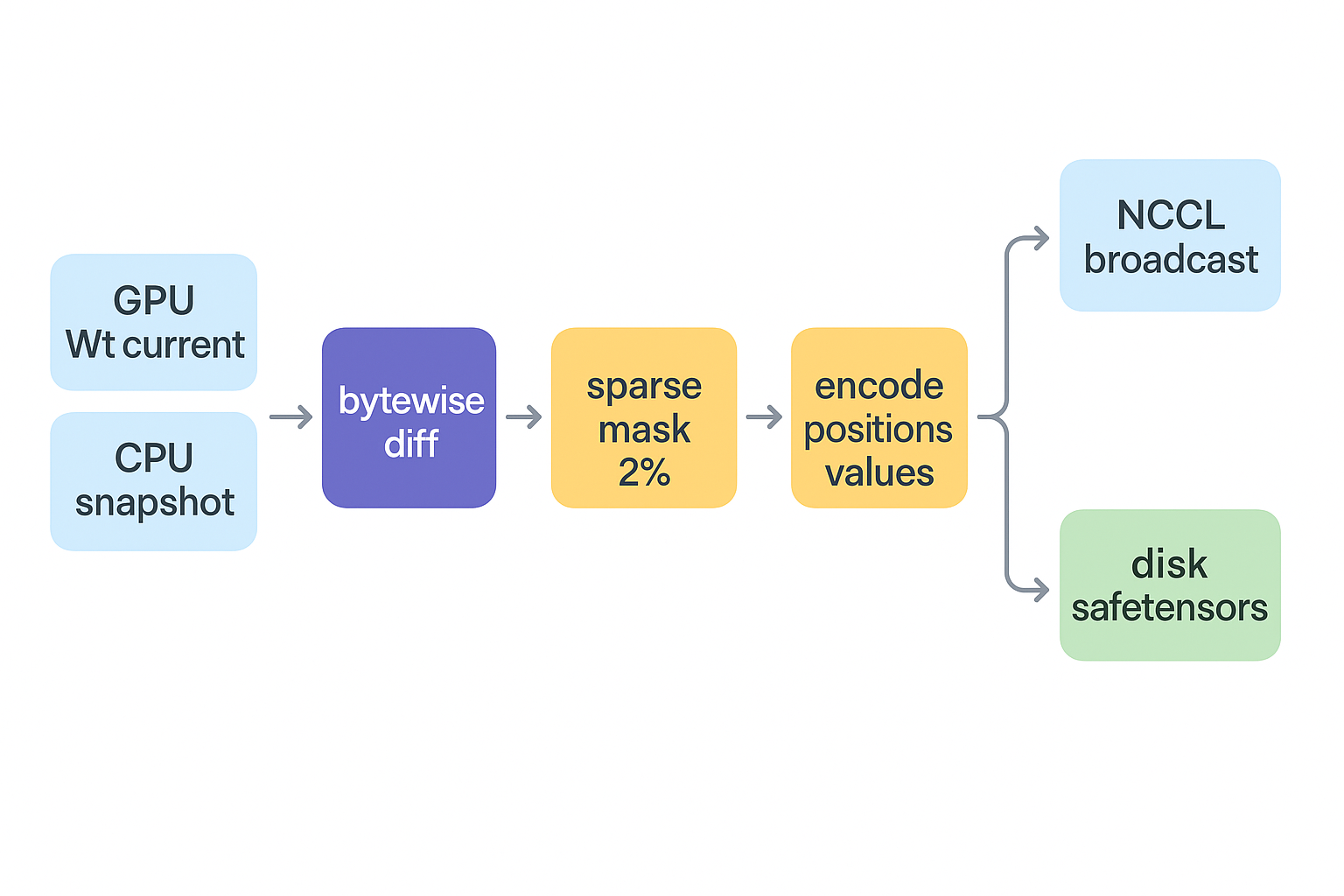
slime delta sync sender pipeline (PP-source rank): the current GPU weights Wₜ and the CPU-pinned full snapshot feed a bytewise diff, producing a sparse mask (~1–3% of elements); the changes are encoded into __positions__ + __values__ and bucketed, then flushed via NCCL broadcast or disk safetensors; after the send, a side-stream copy refreshes the snapshot to the current weights as the next step’s diff baseline.
4.1.1 The four steps of one sync
Every sync, the sender does four things:
-
Diff: compare the current weights against the pinned-CPU snapshot (the last broadcast) byte-by-byte —
current.view(int_dtype) != snapshot.view(int_dtype). Reinterpreting as integers and comparing bytes makes it dtype-agnostic, arithmetic-free, and lossless. -
Encode: pack the changed (position, value) pairs into a
__positions__byte blob, a__values__tensor, and one manifest per parameter. The three encodings differ only in how positions are compressed; values are always sent verbatim in the original dtype:Encoding Position representation Use case indicesint32 absolute position (4 B/nnz) NCCL or fast intra-cluster FS (≥ ~600 MB/s) deltasuint16 gap-delta (uint32 fallback, ~2 B/nnz @2%) mid-bandwidth FS (~300–500 MB/s) deltas_zstddeltaswrapped in zstd L1cross-DC / cross-region shared FS (≤ ~300 MB/s) Why does
deltasget away with 2 bytes whileindicesneeds 4? The difference is whether you store an absolute position or the gap between neighbors.indicesstores each changed element’s absolute index intoparam.view(-1)— a weight tensor easily has tens of millions of elements, so the index range is in the tens of millions, which uint16 (max 65535) can’t hold; it has to be int32 (4 bytes).deltasinstead stores the gap between consecutive changed positions,idx[k] - idx[k-1] - 1. The positions frommask.nonzero()are sorted ascending, so the gap is always positive; and at density p≈2%, on average only 1 in ~50 elements changes (the gap’s expectation is exactly1/p), so the vast majority of gaps are a few dozen, rarely more than a few hundred. For a gap to exceed 65535 you’d need 60k+ consecutive elements unchanged — at 2% density that probability is essentially zero, so uint16 suffices and the position blob halves.If some parameter is sparse enough that a gap really does overflow uint16, it falls back to uint32 at per-parameter granularity (
pos_widthis per-param, see §4.2.4); the receiver reconstructs absolute positions withidx = cumsum(gap + 1) - 1. -
Bucket & flush: accumulate into a bucket up to
--update-weight-buffer-sizebefore sending. Note that the bucket’s two halves live in different places — positions are turned into a host byte sequence during encode (positions.cpu().numpy().tobytes(); small, and they have to be packed into the wire format anyway), while values stay GPU tensors (large; avoids an unnecessary D2H). At flush, each transport completes the missing leg: the NCCL transport pushes positions back to the GPU via one H2D and broadcasts both on the GPU; the disk transport instead pulls values from GPU to CPU and a background thread writes the safetensors (I/O and optional zstd happen off the critical path on a worker thread). -
Snapshot: a side-stream D2H copy of the just-sent values refreshes the snapshot, overlapping the next chunk’s encode.
The sender’s real complexity is almost entirely one thing: how to hide “moving data” and “waiting on the receiver” inside “diff + encode.” One sync’s time splits into compute + transfer + wait, and delta uses three levels of overlap to keep the latter two off the wall-clock. Here they are, from the innermost (CUDA streams) to the outermost (across segments).
4.1.2 Three CUDA streams: hide snapshot movement inside compute
The snapshot is both read (the diff baseline) and written (refreshed to the new baseline for the next step), and it lives in CPU-pinned memory, so it crosses PCIe/NVLink every time. DeltaState splits this across three streams:
- default stream: bytewise diff + sparse encode for the current chunk;
h2d_stream(read, prefetch): bring the next chunk’s old snapshot from CPU to GPU, as input for the diff it’s about to do;d2h_stream(write, write-back): asynchronously copy the current chunk’s just-sent values back into the CPU snapshot, as the next step’s diff baseline.
The two copy streams must be separate, for three reasons:
- No dependency between them, so one stream forces serialization: prefetching the next chunk and writing back this chunk are independent; on one stream they queue in order, the prefetch stuck behind the write-back, and the overlap is gone.
- Copy engines are full-duplex: a GPU’s H2D and D2H copy engines are independent, and PCIe/NVLink can run both directions at once — two streams are what saturate the bidirectional bandwidth.
- Don’t crowd the default stream: a copy on the default stream contends with diff/encode for the same execution queue, which is back to synchronous movement.
Ordering is held by CUDA events, not left to chance: the prefetch records an event on h2d_stream, and compute_diffs does event.wait() before reading that snapshot; the write-back records on the default stream and d2h_stream waits on that event before copying (so the new values are final on the default stream before write-back); flush_snapshot does a synchronize() of all write-backs before the next sync — miss that and the next step’s snapshot is half-new, half-old and the diff is wrong.
4.1.3 Chunk-level overlap: one-step prefetch
“Prefetch the next chunk” from §4.1.2 is a 1-step lookahead in _pipeline_pass: each loop iteration kicks off the async H2D prefetch for the current chunk, then goes back to process the previous chunk. Unrolled, that means “chunk N−1’s compute+encode” and “chunk N’s old-snapshot H2D” run at the same time, so by the time chunk N is processed its snapshot is already in place and the event.wait() barely waits. The snapshot transfer is hidden inside the neighboring chunk’s compute.
4.1.4 Segment-level overlap: 4 expert sub-passes so receiver apply runs alongside encode
The outer level of overlap is between “segments.” _send_weights splits the params into one non-expert segment and four expert segments (_EXPERT_SUBPASSES = 4) — MoE expert params are the bulk, so they get their own segments. Each segment ends with _flush_and_publish, a delivery to the receiver: once a segment is sent, the engine is told to apply it. Splitting into four means that while segment 1 goes out and the engine starts applying it, the sender is already encoding segment 2 — the receiver’s apply runs alongside the sender’s encode, so the apply latency no longer piles up at the end of the sync.
The split works because Megatron splits MoE layers uniformly across PP ranks, so slicing each rank’s expert list into four gives every rank the same flush/publish count, and the end-of-segment barrier never strands a rank. The number 4 is a trade-off — more segments means finer overlap but one extra barrier + notify per segment.
4.1.5 The disk transport’s async write and publish
The disk path (for cross-DC, or whenever there’s no NCCL connectivity between engine and trainer) has heavier async machinery — two extra layers beyond NCCL:
- Background writer thread (
AsyncSafetensorsWriter): a flush only enqueues(positions, values, metadata); the safetensors encode, optional zstd,fsync, and atomicos.replaceall happen on the worker thread, off the encode main thread. The atomic rename is what guarantees the engine never reads a half-written file. - Async publish RPC: at each segment end,
_publish_batchall-gathers each rank’s batch of filenames to rank 0, and a single-thread pool fires theupdate_weights_from_disknotification asynchronously — it doesn’t wait for the engine to finish reading before encoding the next segment. For cross-DC there’s an optional_pre_push_hook(returns a future) that inserts a “wait until the shared FS has actually persisted to the far side” step before the notification, with the notification queued behind that future — so the encode thread isn’t blocked, and the engine never reads a file that hasn’t propagated yet.
4.1.6 How the sync latency splits
The sender wraps the whole update_weights in two timing blocks that map exactly onto the latency a user observes:
delta_encode: diff + encode + send (for disk, also waiting for the writes to land and the snapshot to write back);delta_finalize: wait for the last batch’s receiver apply to land, then resume generation.
Their sum is the sync latency observed at that training step. Splitting into two makes the bottleneck obvious at a glance: piled up in delta_encode means the sender’s encode is the limiter, piled up in delta_finalize means the receiver’s apply is. The sub-pass overlap from §4.1.4 is, in essence, moving apply time that would otherwise land in delta_finalize into the delta_encode window to run in parallel.
Checksum is on the sender too: before each bucket flush,
torch.hash_tensor(XOR-reduce) computes one, which travels with the DeltaSpec on the metadata channel for the receiver to recompute and compare (see §4.2.2). It doesn’t participate in any of the overlap above — it just adds one reduction plus one.item()sync on the critical path, to catch corruption between encode and apply.
The demo below brings these overlap levels together — toggle to Naive mode to see directly how much wall-clock the pipeline saves once transfers and apply are tucked inside compute:
Each chunk goes through prefetch → compute → send → receiver apply. In Pipelined mode, chunk N+1's snapshot prefetch overlaps chunk N's compute (independent h2d / d2h streams), and receiver apply overlaps the next batch's encode; in Naive mode each chunk waits for the previous one to finish entirely. The total work is identical.
4.2 Receiver: NaN-masked overwrite (in SGLang)
This section’s details all come from SGLang PR #26519. The PR is currently mixed with a lot of unrelated commits; the one commit that actually implements the delta receiver is 3f118378 — read that one, with the core logic in a few functions of model_executor/model_runner.py.
Both transports (disk reading files, distributed receiving via NCCL broadcast) funnel into one _apply_delta_payload(encoding, params, positions, values, expected_checksum). The overall flow is in the figure; the points follow.
![slime delta sync receiver apply, inside SGLang (sgl PR #26519): the sparse payload lands on GPU → checksum is re-verified → each parameter is decoded by densifying back into a full-shape NaN tensor (sparse on the wire, dense on apply) → SGLang’s native model.load_weights is reused, wrapped by _delta_apply_context which monkeypatches Tensor.copy_ to do dst[~isnan(src)] = src — an in-place masked overwrite onto the existing GPU weight. How it knows a copy target is a model parameter: see §4.2.7.](/posts/delta-weight-sync/delta-receiver-apply.png)
slime delta sync receiver apply, inside SGLang (sgl PR #26519): the sparse payload lands on GPU → checksum is re-verified → each parameter is decoded by densifying back into a full-shape NaN tensor (sparse on the wire, dense on apply) → SGLang’s native model.load_weights is reused, wrapped by _delta_apply_context which monkeypatches Tensor.copy_ to do dst[~isnan(src)] = src — an in-place masked overwrite onto the existing GPU weight. How it knows a copy target is a model parameter: see §4.2.7.
4.2.1 The two transport entries
NCCL goes through _apply_delta_from_distributed: before the sender broadcasts, an RPC delivers a set of (name, dtype, shape, group_name, DeltaSpec) metadata; based on the shape/dtype it pre-allocates two empty GPU buffers (NCCL is schema-less, so both sides must know what they’re receiving), then asynchronously issues two broadcasts (positions / values), and once they wait() hands off to _apply_delta_payload. It reuses the same NCCL group slime already uses for full-sync (self._model_update_group[group_name]), not a new one.
Disk goes through _apply_delta: a ThreadPoolExecutor (size --update-weight-delta-read-workers, default 4) reads safetensors files concurrently; each binary blob runs through _maybe_zstd_decompress, which auto-detects the zstd magic (0x28B52FFD) and decompresses on demand; then _decode_and_apply_delta_blob manually parses the safetensors header (int.from_bytes(blob[:8]) for header_len, then json.loads for __metadata__) to extract the DeltaSpec, and finally calls _apply_delta_payload.
The two paths diverge on “how the data reaches the GPU,” but converge on “how to apply it once you have it” — the same _apply_delta_payload. That’s the key confluence point in the design.
4.2.2 Checksum: travels with the DeltaSpec on a metadata channel
The first thing _apply_delta_payload does is verify:
actual = _delta_checksum(positions, values) # torch.hash_tensor XOR-reduce
if actual != expected_checksum:
raise RuntimeError("delta checksum mismatch: ...")
The checksum isn’t in the data tensors on the wire — it travels with the DeltaSpec on the metadata channel:
- NCCL: a JSON-string field of the
delta=RPC argument ({"encoding": ..., "params": [...], "checksum": "..."}); the data tensors go separately over NCCL broadcast. - Disk: written into the safetensors file’s
__metadata__(the header’s dedicateddict[str, str]slot).
By the time it arrives, the sender’s int is already deserialized in the DeltaSpec, so the receiver just recomputes and compares.
4.2.3 Per-parameter decode: densify back to a full-shape NaN tensor
For each DeltaParam p in DeltaSpec.params, _decode_delta_one_param does four steps on the GPU:
- Allocate a full-shape NaN buffer:
flat = torch.full((numel,), nan, dtype=p.dtype, device=self.device). This is the receiver’s biggest temporary VRAM cost — it’s where “sparse on the wire, dense on apply” comes from. - Slice this param out of the bucket arrays:
pos_bytes = positions[p.pos_start:p.pos_end],val_slice = values[p.val_start:p.val_end]. - Unpack bytes back into integers:
pos_bytes.view(n, width).to(torch.int64)then bit-opsb[:,0] | (b[:,1]<<8) | ..., vectorized, with zero CPU sync. - Reconstruct absolute indices and scatter:
indicesencoding:idx = unpacked(already absolute)deltas/deltas_zstd:idx = (unpacked + 1).cumsum() - 1(the algebraic inverse of gap encoding, a pure prefix-sum trick)flat.index_copy_(0, idx, val_slice.to(p.dtype))writes values into place.
It returns flat.view(*p.shape) — a full-shape tensor that is NaN at unchanged positions, the trainer’s exact bytes at changed positions.
An easy-to-miss cost: the wire is sparse, but apply densifies back to full shape — each parameter needs a temporary GPU tensor as big as the original as its source. To bound peak VRAM, the PR groups params into chunks of
--update-weight-delta-chunk-bytes(default 512MB) and applies a chunk at a time (see §4.2.5). Ideally this densify could be skipped — vLLM’s #40096 (merged 2026-06) does exactlyparam.data.view(-1).index_copy_(indices, values)straight onto the runtime weight, with no densify and no sender-side CPU snapshot.That said, slime’s “densify and reuse the native
load_weights” approach is arguably the more elegant one: it reuses all of the engine’s existing TP/EP/PP sharding, format conversion, and quantization handling, so it runs the full range of parallelism out of the box; vLLM #40096 bypasses the loader to skip densify, and pays for it by being TP=1/PP=1 only for now. And since the densify is already chunked at 512MB, its actual contribution to peak VRAM is small — the memory you’d save by dropping it is worth far less than the loader’s ready-made parallelism handling you’d give up.
4.2.4 Wire layout & “separating indices from data”
For the slicing above to work, one flush on the wire is actually three things (not two):
__positions__ uint8 byte blob concatenated positions across params
__values__ param-dtype tensor concatenated values across params
DeltaSpec small metadata: encoding + List[DeltaParam] + checksum
DeltaParam is an address book (it carries no data) — just slice offsets and shape:
DeltaParam(
name="layers.0.q.weight",
dtype="bfloat16", shape=[4096, 4096],
pos_start=1024, pos_end=1056, pos_width=2, # byte offsets + 2/4 bytes per position
val_start=512, val_end=528, # element offsets
)
A few precise details:
- Positions use byte offsets, values use element offsets — positions are a uint8 blob and different params can have different
pos_width(uint16 vs uint32 fallback), so bytes are the natural unit; values are a fixed-dtype tensor, where elements are more natural. - pos and val are not at the same offset on the wire — they pair ordinally (“the k-th position goes with the k-th value”), not by byte offset:
positions[start:end] decodes to nnz indices values[start:end] yields nnz values → idx[k] ↔ val[k] pos_widthis per-param, not per-bucket — most params in a bucket use uint16 (at 1–3% density a gap is almost always < 65535), and the rare extremely-sparse param falls back to uint32. The decoder slices each by its ownDeltaParam.pos_width.- A position is a 1D flat index, not a multi-dim coordinate — the decoded index lands directly on
param.view(-1), and only the finalview(*shape)turns it back multi-dimensional.
This is the classic separate-indices-from-data pattern (CSR sparse matrices, Apache Arrow, safetensors itself): one big flat data blob plus a small index describing the structure. The payoff is that NCCL can broadcast one big array and disk needs one file, instead of a scattered fragment per param.
4.2.5 NaN-masked overwrite on top of native load_weights
The core loop of _apply_delta_payload:
with _delta_apply_context(self.model):
chunk = [] # list[(name, tensor)]
chunk_bytes = 0
for param in params:
tensor = self._decode_delta_one_param(...) # full-shape NaN tensor
if chunk and chunk_bytes + size > chunk_byte_cap: # 512MB cap
self.model.load_weights(chunk) # ← native loader
chunk = []; chunk_bytes = 0
chunk.append((param.name, tensor))
chunk_bytes += size
if chunk:
self.model.load_weights(chunk)
A few points:
chunkis alist[(str, torch.Tensor)], not torch params — it’s the “weight stream” SGLang’smodel.load_weights(weights: Iterable[(name, tensor)])interface expects.nameis theDeltaParam.name(the HF name, passed through from the sender’s manifest).- The interface only wants two things: the HF name and a full-shape source tensor. Each model’s
load_weightsinternally handles HF→internal name mapping, QKV split/fuse, quantize, etc., and always ends attensor.copy_(src)writing the GPU weight — which is the exact point the next section’s monkeypatch intercepts. chunk_byte_capbounds the receiver’s VRAM peak, and is a separate layer of batching from the sender’s bucket size: sender bucket size =--update-weight-buffer-size(controls wire frequency); receiver chunk size =--update-weight-delta-chunk-bytes(controls receiver VRAM peak). Independent.
4.2.6 _delta_apply_context: temporarily monkeypatch copy_ / fill_
This is the cleverest step in the whole receiver design. To write a sparse delta back into the weights, the intuitive move is to write your own “sparsity-aware” weight-loading path — but every model family’s load_weights is different, each carrying its own fused-QKV split, quantization, and TP/PP handling. This does the opposite: the engine’s native load_weights is reused unchanged, in full, and it only hooks the Tensor.copy_ / Tensor.fill_ it ultimately lands on, swapping “overwrite the whole tensor” for “overwrite only the non-NaN positions.” Sparse semantics are injected quietly at the lowest level, and all the per-model conversion, quantization, and parallelism handling above is reused as-is — the receiver re-implements almost no model-specific loading logic.
Concretely, _delta_apply_context is a contextmanager that temporarily rewrites the process-level torch.Tensor.copy_ and Tensor.fill_ on entry and restores them on exit:
@contextlib.contextmanager
def _delta_apply_context(model):
is_param_target = _param_storage_index(model) # see §4.2.7
original_copy_, original_fill_ = Tensor.copy_, Tensor.fill_
def patched_copy_(self, src, *args, **kw):
if is_param_target(self) is not None: # is the target a model weight?
mask = ~torch.isnan(src)
self[mask] = src[mask] # in-place, only non-NaN positions
return self
return original_copy_(self, src, *args, **kw) # not a weight → as-is
def patched_fill_(self, value):
if is_param_target(self) is not None and isnan(value):
return self # fill_(NaN) onto a weight → no-op
return original_fill_(self, value)
Tensor.copy_ = patched_copy_
Tensor.fill_ = patched_fill_
try: yield
finally: restore
Why copy_ is patched: a model’s native load_weights always ends in tensor.copy_(src). Unpatched, the full NaN-containing src would overwrite the weight directly — every unchanged position becomes NaN and the model is ruined. Patched, copy_ consults the mask and overwrites only the non-NaN positions — in-place, directly onto the existing GPU weight, with no new weight tensor allocated.
Why fill_ is patched too (and only for the NaN case): copy_ isn’t the only path that writes a weight. Slice assignment param[:] = scalar, Tensor.zero_(), and some of PyTorch’s internal __setitem__ go through fill_. A single param.fill_(NaN) anywhere would smear the whole weight to NaN. But patched_fill_ only intercepts the NaN case — because a loader legitimately calls param.fill_(0), zero_(), scale.fill_(1.0), etc. for initialization, and making every fill_ a no-op would break the loader. NaN is the delta-apply sentinel, and a normal load_weights will never use NaN as a fill value, so intercepting only NaN is safe.
post_load_weights (fp8 scale / MoE bias post-processing) is wrapped to temporarily restore the native copy_/fill_ — that part is pure arithmetic post-processing and must not be masked. The design guarantees: the main load_weights phase runs patched, the post-processing phase runs native.
4.2.7 How it recognizes “the target is a model weight”: _param_storage_index
How does is_param_target(self) is not None in patched_copy_ work? Via a precomputed lookup table mapping GPU memory-address ranges → owner param:
def _param_storage_index(model):
starts, ends, owners = [], [], []
for tensor in named_parameters() + named_buffers():
ptr = tensor.data_ptr() # GPU memory pointer (int)
starts.append(ptr); ends.append(ptr + tensor.nbytes)
owners.append(tensor)
# sort by start, bisect for O(log n) range lookup
def find_parent(dst):
idx = bisect.bisect_right(starts, dst.data_ptr()) - 1
if 0 <= idx and starts[idx] <= dst.data_ptr() < ends[idx]:
return owners[idx]
return None
return find_parent
Key properties:
data_ptr()is a GPU device pointer (an int like0x7f8c01a40000), not an ordinal index.- Slices / views hit automatically: a PyTorch view only changes metadata, the underlying storage is the same, so
param[:, :half].data_ptr()naturally falls in the parent param’s[start, end)range. No need to enumerate every view form by hand. - Scratch buffers are excluded automatically: a temp tensor’s pointer falls in a gap, doesn’t hit, and goes through native
copy_— untouched by the mask. - Pure CPU + O(log n): n is usually a few hundred to a few thousand, a bisect is a few hundred nanoseconds, negligible next to a
copy_kernel launch.
4.2.8 Why it’s lossless and drift-free
The whole thing is “byte-for-byte overwrite of the trainer’s exact bytes,” with no arithmetic (it’s not w += delta), so it’s bit-identical by construction and has none of the cross-step floating-point accumulation drift an additive-delta scheme has — which means no periodic full re-sync is needed to correct drift. That’s the fundamental difference from additive schemes.
4.2.9 Known defect: silent drift on failure (THUDM/slime#2104)
On a failed apply (checksum / read / decode error) the receiver just catches, logs, and returns (False, msg), while the sender’s _finalize_sync discards that return value. Because the sender’s snapshot has already advanced before the send, a silently-failed apply leaves the sender believing those positions are synced — it won’t diff them again — so that part of the receiver’s weights drifts permanently, until a restart re-seeds. Over NCCL it either succeeds or takes down the whole job, so it basically can’t trigger; over disk across DCs the probability is non-zero. We filed issue #2104 to track it; there’s an open fix PR #2119; in our verl implementation we just trigger a force full re-sync on failure to plug it.
4.3 How invasive is the change?
- Very low intrusion into the training side: pure subclassing plus new flags, with no changes to loss, optimizer, or the existing full-sync path, and default behavior unchanged (all of it isolated in one new file, independent of existing paths).
- But one real resource cost: the sender’s pinned-CPU full snapshot, roughly a full model resident in host memory; the initial seed blocks ~50s on a 355B model. It trades host memory + a one-time init for per-step traffic.
- Needs a matching engine build: the receiver capability comes from SGLang PR #26519, so deploy a SGLang build that includes it (bring your own until the PR lands upstream).
- One explicit restriction:
delta + colocateis rejected at argparse. Colocate goes through CUDA IPC, passing only a ~64 B memory handle between processes — there are no bytes for delta to save, and it would only add snapshot + diff + encode overhead.
4.4 Does it compose with RDMA?
Yes, and the two are orthogonal. slime splits sync into two independent dimensions:
- “What to send” = mode:
full/delta - “How to transport” = transport:
nccl/disk
| mode | transport | Behavior |
|---|---|---|
full |
nccl |
Default path: broadcast each HF weight chunk over the trainer-engine NCCL group |
full |
disk |
Write a full HF checkpoint, then the engine reloads via update_weights_from_disk |
delta |
nccl |
Broadcast the sparse changed positions and values over NCCL |
delta |
disk |
Write sparse safetensors to a shared FS, then push to the engine to apply |
The key points:
delta + ncclis “delta over NCCL.” NCCL itself runs over IB / RoCE — i.e. on top of an RDMA fabric — so you get both RDMA’s bandwidth and the ~1–3% byte reduction, stacked rather than in conflict. slime’s docs position the NCCL transport as the intra-DC validation baseline, for verifying the wire encoding and apply logic.delta + disk(shared FS / object store) targets cross-DC / cross-region setups without RDMA. There full broadcast is infeasible, while a sparse delta (~3% density, ~5GB for a 355B model) is acceptable on a shared FS at hundreds of MB/s.
The conclusion: delta isn’t a replacement for RDMA — it cuts the bytes further when RDMA is present, and keeps RL decoupled when it isn’t.
5. Closing thoughts
A plain observation — most weights don’t change after one RL step — reshaped RL’s cost structure in a matter of months: trainer and rollout can run over ordinary networks and even across regions, with tokens/$ that can beat a reserved RDMA cluster (per SparrowRL’s report).
A few open questions worth pursuing:
- Could a more aggressive lossy delta (e.g. dropping the tiniest changes) compress further without hurting convergence?
- For long training runs, if one uses additive instead of overwrite, how is the cross-step accumulation drift bounded? (slime sidesteps this with pure overwrite.)
- In MoE settings, does the sparsity hold for expert weights? Could differing expert activation frequencies make the delta distribution uneven?
These may be directions for the next phase.
References
- PULSE / PULSESync, arXiv 2602.03839
- SparrowRL (RL over Commodity Networks), arXiv 2602.11456
- SparseRL-Sync (Helix), arXiv 2605.07330
- Fireworks, “Frontier RL Is Cheaper Than You Think”
- Cursor, Composer 2 Technical Report
- Hugging Face TRL, “Shipping a Trillion Parameters With a Hub Bucket: Delta Weight Sync in TRL”
- slime, docs/en/advanced/delta-weight-sync.md
- vLLM #40096 (sparse NCCL in-place, merged), #44353 (weight sync refactor), issues #31848 / #39451
- Biao He, “Optimizing Weight Sync in slime”