TL;DR
在 LLM 的 RL post-training 中,trainer 每完成一个 optimizer step,就需要把更新后的权重同步给负责 rollout 的 inference engine。在解耦(disaggregated)架构下,这一步长期被视为必须依赖高带宽 RDMA 的环节——同步开销随模型规模线性增长,并主导整个 sync 阶段。
2026 年上半年,学术界、工业界与开源社区几乎同时给出了同一个观察并加以利用:在典型的 RL 学习率下,每个 step 之后真正发生变化的权重只占很小一部分(在 BF16 表示下,超过 99% 的元素逐字节未变)。因此只传输变化的部分(delta),即可将通信量降低约两个数量级,且重建无损、bit-identical。这把权重同步从一个依赖 RDMA 网络的硬件问题,转化为一个如何编码稀疏 delta 的软件问题——使得 RL 训练能够运行在普通以太网,甚至跨数据中心的共享存储之上。
本文先说明这一观察的来源与依据,再以 slime 的实现为完整实例,拆解要落地 delta weight sync 需要在系统的哪些环节进行改动。
1. 背景:weight sync 为什么是瓶颈
现代 RL 框架普遍将 trainer(Megatron / FSDP)与 rollout/inference engine(SGLang / vLLM)解耦:两者采用不同的并行策略与算子实现,往往运行在不同的进程、节点乃至数据中心。由此产生一个不可回避的步骤:每次策略更新后,必须将 trainer 的新权重同步给 inference engine,否则采样所用的是过期策略。
默认做法是 full broadcast:把全部参数从 trainer 广播给所有 inference rank(典型实现是 trainer 的 rank 0 与 inference engine 的所有 rank 组成一个 NCCL 通信组)。其开销随模型规模线性增长,在解耦架构中通常主导整个 sync 阶段。
社区早期的优化方向是「把搬运做快」而非「少搬一些」。例如 slime 团队将 full-sync 延迟从约 60s 优化到约 7s——通过 async tensor gathering、bucketing(将约 2000 次 HTTP 调用降到约 120 次)、tensor flattening 以及 weight loading 缓存等手段(详见 Biao He 的博客)。但这本质上仍在传输全量权重。
当网络从 RDMA 退化为普通商用网络(带宽量级为数百 MB/s)时,full broadcast 便不再可行。SparseRL-Sync 论文(arXiv 2605.07330)指出,现有 RL 系统(OpenRLHF、veRL、StreamRL 等)的 rollout 优化大多依赖集群内高带宽网络;一旦迁移到商用网络,full broadcast 的有效吞吐很低,同步一个 8B 模型即需要超过 100 秒。模型规模更大、且需要跨 region 时,full broadcast 在工程上已不具可行性。
2. 关键观察:RL 的权重更新本身高度稀疏
转折来自 PULSE(arXiv 2602.03839,Erfan Miahi @Covenant AI,Eugene Belilovsky @Mila)对这一现象的系统化分析。其核心论点是:
在典型的 RL post-training 学习率下,Adam 的许多更新量小到在 cast 回 BF16 之后不可见——更新落在了当前权重值的 BF16 舍入阈值以下。因此一个 step 之后,绝大多数权重元素的字节表示并未改变。
PULSE 将此称为 compute-visible sparsity,并报告约 99% 的 per-step 更新在 BF16 cast 后不可见。其他独立工作也给出了高度一致的测量:
- SparrowRL(arXiv 2602.11456)报告每个 step 约 1% 的参数元素发生变化;
- Fireworks(Frontier RL Is Cheaper Than You Think)报告相邻 checkpoint 之间超过 98% 的 bf16 权重 bit-equivalent,平均 delta 约为全量的 1.98%;
- slime 文档(delta-weight-sync.md)以约 3% 的密度为典型工作点,对应 355B 模型约 5GB 的 delta。
既然如此,便无需每步传输全量,只需传输变化位置的索引与新值(indices + values),由接收端在对应位置覆盖。由于是逐元素覆盖、写入 trainer 的精确字节,整个过程不涉及任何算术运算,因而无损、bit-identical——也不会出现 additive delta 方案中的浮点累积漂移问题。通信量大致与密度成正比:约 1–3% 的密度对应约两个数量级的通信量下降。
3. 三条线在四个月内独立收敛
同一个想法在 2026 年上半年被学术界、工业界、开源社区近乎同时、各自独立地落地。各家的核心做法其实一致——发送稀疏 delta、无损重建、压缩比几十到上百倍(具体数字见下表),真正的区别只在切入的角度:
学术 / 论文(自 2 月起)
- PULSE / PULSESync(arXiv 2602.03839)最早把它讲清楚:提出 compute-visible sparsification,并论证 sparse BF16 patch 能 bit-identical 重建、对传输错误鲁棒。
- SparrowRL(arXiv 2602.11456)把目标网络从 RDMA 拉到普通以太网 / WAN:配多流传输 + 与 rollout 生成重叠,论证这套在 commodity network 上也能打——tokens/$ 甚至高过预留的 RDMA 集群。
- SparseRL-Sync / Helix(arXiv 2605.07330,Scitix,Megatron + SGLang)给出最极端的稀疏度证据:元素级稀疏度超过 99%。
工业界系统(自 3 月起)
- Fireworks(Frontier RL Is Cheaper Than You Think,3-23)把它跑进生产:rollout/training 解耦、跨 region 更新,且 diff 基准放在相邻 checkpoint 之间,区别于多数实现的「step 前后」。
- Cursor(Composer 2 技术报告)多了一个独特能力:mid-trajectory 更新——同一条序列里靠后的 token 可以由比靠前 token 更新的 checkpoint 生成。
开源框架(自 5 月起)
- Hugging Face TRL(Delta Weight Sync in TRL,5-27)把传输介质做到最轻:权重只经一个 HF Hub bucket 流转,完全解耦,无需 RDMA 或 VPN。
- slime(THUDM) 是本文下一节详细拆解的实例。
引擎层也在跟进:vLLM 已把 sparse in-place weight update 落成原生能力(#40096,2026-06 merged,目前仅 NCCL、TP=PP=1)。
下表概括各家的工程取舍(数据来源见上文各条链接):
| 实现 | 传输介质 | 编码 | diff 基准 | 无损 | 报告的压缩比 |
|---|---|---|---|---|---|
| PULSE | NCCL | sparse BF16 patch | step 前后 | 是 | 100×+ |
| SparrowRL | 多流 / commodity net | sparse delta | step 前后 | 是 | 79×(Qwen3-8B payload) |
| Fireworks / Cursor | 跨 region 对象存储 (S3) | 压缩 delta | 相邻 ckpt | — | ~94% 传输量下降(1.98% delta) |
| TRL | HF Hub Bucket (Xet) | sparse safetensors | step 前后 | 是 | 1.2GB→20–35MB(Qwen3-0.6B) |
| slime | NCCL 或 disk/共享FS | indices / deltas / deltas_zstd | pinned-CPU snapshot | 是 | ~3% 密度(355B 约 5GB) |
分歧主要集中在三个维度:传输介质(NCCL / 对象存储 / 共享 FS)、位置编码方式,以及 diff 的基准。下面以 slime 将这些具体化。
4. slime 的 delta weight sync 实现详解
slime(THUDM 的 RL 后训练框架,Megatron + SGLang)在其文档 delta-weight-sync.md 中给出了一套完整且可读的实现,适合作为「落地 delta sync 需改动哪些环节」的参考标本。以下分析基于 slime 主分支的源码与文档。
4.0 改动落在系统的哪些位置
落地 delta sync,改动分两头,且有一个容易被忽视的关键点:发送端和接收端都要改,而接收端的改动落在引擎里,不在 slime。
- 发送端(slime 框架内):新增一个继承 full-sync 的子类,复用父类已有的 NCCL group、TP/EP gather 与 HF 格式转换,只重写 diff / 编码 / 发送这几步。真正新增的资源只有一样——一份常驻 host 的 pinned-CPU 全量权重快照,作为每步 bytewise diff 的基准。这是 delta 相对 full broadcast 唯一的净增开销(full broadcast 不需要任何快照),且首次启动要做一次完整遍历来 seed(slime 文档标注 355B 上约 50s)。剩下就是入口处的模式选择,加一组新的
--update-weight-*参数。 - 接收端(引擎内,不在 slime):真正把 sparse delta 写回权重的逻辑在 SGLang,由一个独立 PR(sgl-project/sglang#26519)提供;slime 这边只有一层很薄的 shim 去 import 它的数据结构。需要注意的是,跑 slime delta sync 要用一个包含这个 receiver 的 SGLang build——该 PR 进主分支前,先自备一个即可。
所以第一个要点是:delta weight sync 并非纯框架特性。发送端要能编码 sparse delta、接收端引擎要能 apply sparse delta,两者缺一不可;后者由 SGLang 侧提供,配套上对应的 build 即可。
下面分两头展开:发送端(§4.1)与接收端(§4.2)。
4.1 发送端 pipeline(仅在 PP-source rank 上执行)
下图概括发送端一次 sync 的整体数据流,下面再逐步展开。
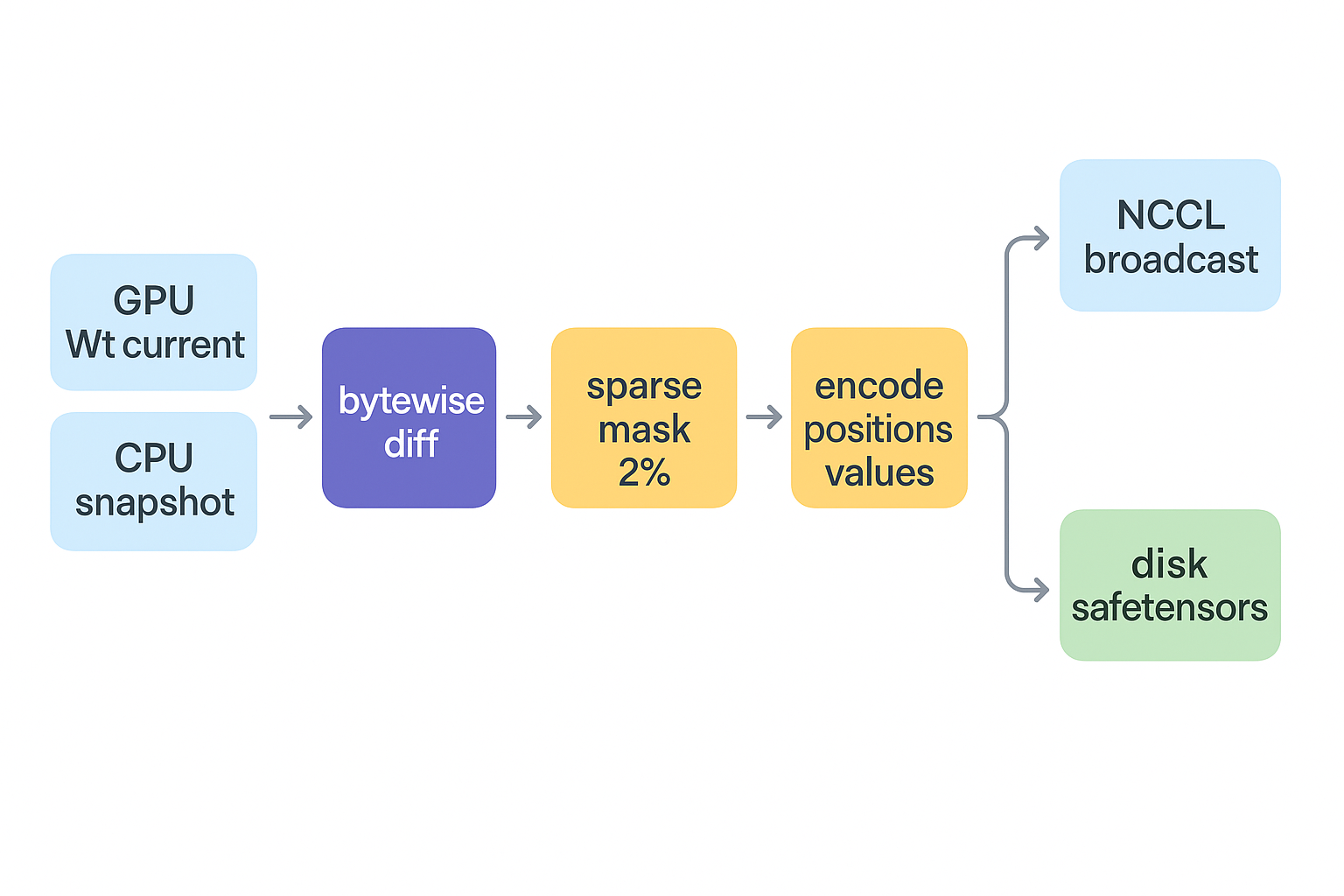
slime delta sync 发送端流水线(PP-source rank):GPU 上的当前权重 Wₜ 与 CPU pinned 的全量快照做 bytewise diff,得到稀疏 mask(约 1–3% 元素),编码成 __positions__ + __values__,bucket 后经 NCCL 广播或 disk safetensors 发出;发送完成后再用 side stream 把快照更新为当前权重,作为下一步的 diff 基准。
4.1.1 一次 sync 的四步
每次 sync,发送端执行四步:
-
Diff:将当前权重与 pinned-CPU snapshot(上一次广播的快照)做逐字节比较——
current.view(int_dtype) != snapshot.view(int_dtype)。即按整数位重新解释后逐字节比较,因而与 dtype 无关、不涉及算术、无损。 -
Encode:将变化的 (position, value) 打包为
__positions__字节 blob、__values__tensor 以及每个参数一份 manifest。三种编码仅决定 position 的压缩方式,value 始终按原 dtype 原样发送:编码 position 表示 适用场景 indicesint32 绝对位置(4 B/nnz) NCCL 或快速集群内 FS(≥ 约 600 MB/s) deltasuint16 gap-delta(uint32 兜底,约 2 B/nnz @2%) 中等带宽 FS(约 300–500 MB/s) deltas_zstddeltas再套一层 zstd L1跨 DC / 跨 region 共享 FS(≤ 约 300 MB/s) 为什么
deltas用 2 字节就够、而indices要 4 字节?区别在于存的是绝对位置还是相邻间隔。indices存的是每个变化元素在param.view(-1)里的绝对下标——一个权重张量动辄上千万个元素,下标范围就有上千万,uint16(上限 65535)根本装不下,只能用 int32(4 字节)。deltas改存相邻两个变化位置之间的间隔idx[k] - idx[k-1] - 1。mask.nonzero()出来的位置天然升序,间隔恒为正;而在密度 p≈2% 下,平均每约 50 个元素才有一个变化(间隔的期望正是1/p),绝大多数间隔只有几十、极少超过几百。一个间隔要超过 65535,意味着连续 6 万多个元素一个都没变——在 2% 密度下这概率约等于零,所以 uint16 足够,位置 blob 体积直接减半。万一某个参数稀疏到间隔真爆了 uint16,就按参数粒度回退到 uint32 兜底(
pos_width是 per-param 的,见 §4.2.4);接收端再用idx = cumsum(gap + 1) - 1把间隔累加还原成绝对下标。 -
Bucket 与 flush:按
--update-weight-buffer-size累积到一个 bucket 再发送。值得明确的是,bucket 内的两部分分别住在不同的地方——positions 在 encode 阶段就已经positions.cpu().numpy().tobytes()落成 host 字节序列(小、且本来就要 pack 成 wire 格式),values 则始终保留为 GPU 张量(大、避免不必要的 D2H)。flush 时按 transport 各自补上最后一步搬运:NCCL transport 把 positions 经一次 H2D 推回 GPU,两者一起在 GPU 上 broadcast;disk transport 反过来把 values 从 GPU 拉回 CPU,再由后台线程写 safetensors(I/O 与可选 zstd 压缩在工作线程做,不阻塞关键路径)。 -
Snapshot:将刚发送的 value 通过 side-stream 做 D2H 拷贝以更新 snapshot,与下一 chunk 的 encode 重叠。
发送端真正的复杂度,几乎全在一件事上:怎么把「搬数据」和「等接收端」这两段时间藏进「算 diff + 编码」里。一次 sync 的耗时可以拆成「算 + 搬 + 等」三块,delta 用三级重叠尽量让后两块不单独占 wall-clock。下面从最内层(CUDA stream)到最外层(段间)逐级展开。
4.1.2 三条 CUDA stream:把搬快照藏进 compute
snapshot 既要读(当作 diff 的基准),也要写(发送后更新成新基准给下一步用),而它常驻 CPU pinned 内存,每次都要跨 PCIe/NVLink 搬一趟。DeltaState 为此用了三条 stream 分工:
- 默认 stream:对当前 chunk 算 bytewise diff + 稀疏编码;
h2d_stream(读,预取):把下一个 chunk 的旧快照从 CPU 搬上 GPU,给它将要做的 diff 当输入;d2h_stream(写,回写):把当前 chunk 刚发出去的新值异步搬回 CPU 快照,作为下一步的 diff 基准。
两条拷贝 stream 必须分开,原因有三:
- 彼此无依赖,合一条就被迫串行:H2D 预取下一块和 D2H 回写这一块之间没有数据依赖,放同一条 stream 会按入队顺序排队,预取被回写堵在后面,重叠就没了。
- copy engine 是全双工的:GPU 的 H2D / D2H 拷贝引擎相互独立,PCIe/NVLink 上下行能同时跑,两条 stream 才能占满双向带宽。
- 不能挤默认 stream:拷贝若放默认 stream,会和 diff/encode 抢同一条执行队列,等于退回到同步搬运。
顺序靠 CUDA event 兜底,并非裸跑:预取在 h2d_stream 上 record event,compute_diffs 里 event.wait() 之后才读那份快照;回写先在默认 stream record、d2h_stream 等到这个 event 之后才搬(保证新值在默认 stream 上算定稿了再回写);flush_snapshot 在进入下一次 sync 前 synchronize() 掉所有回写——这一步漏了的话,下一步的快照会是半新半旧,diff 出来全是错的。
4.1.3 chunk 级重叠:错一步的预取
§4.1.2 里「预取下一个 chunk」具体靠 _pipeline_pass 的一个 1-step lookahead:每轮循环先给当前 chunk 发起异步 H2D 预取,再回头处理上一个 chunk。展开看就是「处理 chunk N−1 的 compute+encode」和「chunk N 的旧快照 H2D」同时在跑,等轮到处理 chunk N 时它的快照早已就位,那句 event.wait() 基本不用等。搬快照的时间就这样被藏进了相邻 chunk 的 compute。
4.1.4 段级重叠:expert 切 4 个 sub-pass,让接收端 apply 与编码并行
更外层的一级重叠发生在「段」之间。_send_weights 把参数分成非 expert 一段、expert 四段(_EXPERT_SUBPASSES = 4)——MoE 的 expert 参数量是大头,单独拆开。每段末尾的 _flush_and_publish 是一次对接收端的交付:发完这段就通知引擎 apply。切成四段之后,第一段发出去、引擎开始 apply 的同时,发送端已经在编码第二段了——接收端的 apply 和发送端的 encode 并行起来,apply 的耗时不再整块堆在 sync 末尾。
切分能成立有个前提:Megatron 把 MoE 层在 PP rank 间均匀切,所以按各 rank 自己的 expert 列表平均切四份,每个 rank 的 flush/publish 次数都一致,段末的 barrier 不会有人多等。4 这个数字是个折中——段越多重叠越细,但每段都要多付一次 barrier + 通知的开销。
4.1.5 disk transport 的异步落盘与发布
disk 路(跨 DC、或引擎与 trainer 之间没有 NCCL 连通时用)的异步更重,比 NCCL 多两层:
- 后台写盘线程(
AsyncSafetensorsWriter):flush 只把(positions, values, metadata)入队,safetensors 编码、可选 zstd 压缩、fsync、os.replace原子改名都在工作线程里做,不占编码主线程。用原子改名是为了让引擎永远读不到写了一半的文件。 - 异步发布 RPC:每个段末
_publish_batch把各 rank 这批的文件名 all-gather 到 rank 0,由一个单线程池异步发出update_weights_from_disk通知,发完不等引擎读完返回就继续编码下一段。跨 DC 时还能挂一个_pre_push_hook(返回一个 future),把「等共享 FS 真正持久化到对端可见」这一步插在发通知之前、通知排在这个 future 之后——既不阻塞编码主线程,又保证引擎不会去读还没同步过去的文件。
4.1.6 一次 sync 的延迟怎么拆
发送端把整个 update_weights 用两个计时块切开,正好对应用户能观测到的延迟:
delta_encode:算 diff + 编码 + 发送(disk 还要等写盘落地、回写快照);delta_finalize:等最后一批的接收端 apply 落地,再恢复推理(resume generation)。
两段之和就是这一步训练观测到的 sync 延迟。拆成两段的好处是一眼能看出瓶颈在哪:堆在 delta_encode 说明卡在发送端编码,堆在 delta_finalize 说明卡在接收端 apply。§4.1.4 的 sub-pass 重叠,本质就是把本来会落在 delta_finalize 的那段 apply 时间,尽量挪进 delta_encode 期间并行掉。
checksum 这一步也在发送端:每个 bucket flush 前用
torch.hash_tensor(XOR-reduce)算一次,随 DeltaSpec 走元数据通道发给接收端,后者重算比对(见 §4.2.2)。它不参与上面任何重叠,只在关键路径上加一次规约加一次.item()同步,用来兜住 encode 到 apply 之间的传输损坏。
下面这张图把上面几级重叠合起来看——切到 Naive 模式对比一下,就能直观看到流水线把搬运和 apply 藏进 compute 之后省下了多少 wall-clock:
说明:每个 chunk 走 预取→compute→send→receiver apply 四步。Pipelined 下 chunk N+1 的快照预取与 chunk N 的 compute 重叠(h2d / d2h 独立 stream),receiver apply 又与后一批的 encode 重叠;Naive 下每个 chunk 等上一个彻底做完才开始。两者工作量相同。
4.2 接收端:NaN-masked overwrite(位于 SGLang)
这一节的细节都来自 SGLang PR #26519。这个 PR 现在混了不少无关提交,真正实现 delta receiver 的只有其中一个 commit——直接看 3f118378 即可,核心逻辑集中在 model_executor/model_runner.py 的几个函数里。
两种 transport(disk 读文件、distributed 经 NCCL broadcast 收)最终都汇入同一个 _apply_delta_payload(encoding, params, positions, values, expected_checksum)。整体流程如下图,下面逐点展开。
![slime delta sync 接收端 apply(在 SGLang 内,sgl PR #26519):稀疏 payload 上 GPU → 校验 checksum → 逐参数 decode 时 densify 回全尺寸 NaN 张量(wire 稀疏但 apply 不稀疏)→ 复用原生 model.load_weights,外面用 _delta_apply_context 临时 monkeypatch Tensor.copy_,做 dst[~isnan(src)]=src 的 in-place masked 覆盖,直接写回已有 GPU 权重。如何判断「目标是模型权重」见 §4.2.7。](/posts/delta-weight-sync/delta-receiver-apply.png)
slime delta sync 接收端 apply(在 SGLang 内,sgl PR #26519):稀疏 payload 上 GPU → 校验 checksum → 逐参数 decode 时 densify 回全尺寸 NaN 张量(wire 稀疏但 apply 不稀疏)→ 复用原生 model.load_weights,外面用 _delta_apply_context 临时 monkeypatch Tensor.copy_,做 dst[~isnan(src)]=src 的 in-place masked 覆盖,直接写回已有 GPU 权重。如何判断「目标是模型权重」见 §4.2.7。
4.2.1 两个 transport 入口
NCCL 走 _apply_delta_from_distributed:在 sender broadcast 前,先通过 RPC 拿到一组 (name, dtype, shape, group_name, DeltaSpec) 元数据,根据其中的 shape/dtype 预先在 GPU 上 alloc 两块 empty buffer(NCCL 是无 schema 的,必须双方都知道接什么),再异步发起两次 broadcast(positions / values),最后 wait() 齐了交给 _apply_delta_payload。这里复用的是 slime 原本 full-sync 用的同一个 NCCL group(self._model_update_group[group_name]),不另建组。
Disk 走 _apply_delta:根据 --update-weight-delta-read-workers(默认 4)开一个 ThreadPoolExecutor 并发读 safetensors 文件;读出来的二进制 blob 通过 _maybe_zstd_decompress 自动检测 zstd magic(0x28B52FFD)按需解压;然后 _decode_and_apply_delta_blob 手动 parse safetensors 头(int.from_bytes(blob[:8]) 拿 header_len,再 json.loads 取 __metadata__)从中提取 DeltaSpec,最后调 _apply_delta_payload。
两条路在「数据怎么到 GPU」上分叉,但「拿到后怎么 apply」共用同一个 _apply_delta_payload——这是设计上的关键汇流点。
4.2.2 Checksum:随 DeltaSpec 走「元数据通道」
_apply_delta_payload 的第一件事是 verify:
actual = _delta_checksum(positions, values) # torch.hash_tensor XOR-reduce
if actual != expected_checksum:
raise RuntimeError("delta checksum mismatch: ...")
checksum 不在 wire 上的数据张量里,而是和 DeltaSpec 一起走元数据通道:
- NCCL:作为
delta=RPC 参数的 JSON 字符串字段({"encoding": ..., "params": [...], "checksum": "..."});数据张量另走 NCCL broadcast。 - Disk:写进 safetensors 文件的
__metadata__字段(safetensors header 里专门dict[str, str]元数据 slot)。
收到时 sender 端的 int 已经在 DeltaSpec 里反序列化好,receiver 重算后比对即可。
4.2.3 单参数解码:densify 回全尺寸 NaN 张量
对 DeltaSpec.params 里的每个 DeltaParam p,_decode_delta_one_param 在 GPU 上做 4 步:
- 开一块全 shape 的 NaN buffer:
flat = torch.full((numel,), nan, dtype=p.dtype, device=self.device)。这是 receiver 侧最大的临时显存开销——「wire 稀疏但 apply 不稀疏」就是这里来的。 - 从 bucket 大数组里切出这个 param 的 slice:
pos_bytes = positions[p.pos_start:p.pos_end]、val_slice = values[p.val_start:p.val_end]。 - 字节反 pack 成整数:
pos_bytes.view(n, width).to(torch.int64)后做位运算b[:,0] | (b[:,1]<<8) | ...,向量化、零 CPU 同步。 - 反算成绝对 index 并散射:
indices编码:idx = unpacked(本来就是绝对位置)deltas/deltas_zstd编码:idx = (unpacked + 1).cumsum() - 1(gap 编码的代数逆,pure prefix-sum trick)flat.index_copy_(0, idx, val_slice.to(p.dtype))把值写到对应位置。
返回 flat.view(*p.shape)——一个未变位置=NaN、变化位置=trainer 的精确字节的全尺寸张量。
这里有个容易忽略的代价:wire 上是稀疏的,但 apply 时被「densify」回了全尺寸——每个参数都要临时分配一块和原参数等大的 GPU 张量作为 source。为控制峰值显存,PR 按
--update-weight-delta-chunk-bytes(默认 512MB)把多个 param 攒成 chunk 再统一 apply(详见 §4.2.5)。理想情况下这次 densify 是能省掉的——vLLM 的 #40096(2026-06 merged)就直接param.data.view(-1).index_copy_(indices, values)把稀疏值写回 runtime 权重,全程不 densify、也不需要发送端那份 CPU 快照。不过说实话,slime 这种「densify 一下 + 复用原生
load_weights」的做法反而更优雅:它顺带复用了引擎里处理 TP/EP/PP 分片、格式转换、量化的全部逻辑,一上来就能跑各种并行;而 vLLM #40096 为了省掉 densify 绕开了 loader,代价是目前只支持 TP=1/PP=1。况且 densify 已经按 512MB 分了 chunk,对峰值显存的实际贡献其实很有限——省掉它换来的那点显存,远不如丢掉 loader 里现成的并行处理来得可惜。
4.2.4 wire layout & 「索引和数据分离」
为了让上一步的切片成立,wire 上一个 flush 其实是 3 样东西(不是 2 样):
__positions__ uint8 字节 blob 多个 param 的 positions 拼接
__values__ param-dtype 张量 多个 param 的 values 拼接
DeltaSpec 小元数据:encoding + List[DeltaParam] + checksum
DeltaParam 是「地址簿」(里面不带数据),只带切片偏移和形状:
DeltaParam(
name="layers.0.q.weight",
dtype="bfloat16", shape=[4096, 4096],
pos_start=1024, pos_end=1056, pos_width=2, # 字节偏移 + 每位置 2/4 字节
val_start=512, val_end=528, # 元素偏移
)
几个关键的精确细节:
- positions 用字节偏移,values 用元素偏移——因为 positions 是 uint8 blob、且不同 param 的
pos_width可以不同(uint16 vs uint32 fallback),字节是自然单位;values 是固定 dtype 的张量,元素更直观。 - pos 和 val 不在 wire 上同一个 offset——它们是「第 k 个 position 对应第 k 个 value」的 ordinal 配对,不是「同字节 offset」配对:
positions[start:end] 解出 nnz 个 idx values[start:end] 取出 nnz 个 val → idx[k] ↔ val[k] pos_width是 per-param 不是 per-bucket——同一 bucket 里大多数 param 用 uint16(密度 1-3% 下 gap 几乎总 < 65535),个别极端稀疏的 param 退 uint32。decoder 看每个DeltaParam.pos_width各自切。- position 是 1D flat index,不是多维坐标——decode 出来的索引直接落在
param.view(-1)上,最后一步view(*shape)才变回多维。
这是个经典「索引和数据分离」模式(CSR 稀疏矩阵 / Apache Arrow / safetensors 自己也是这样):一份大数据扁平 + 一份小索引描述结构。好处是 NCCL 可以一次 broadcast 整块大数组、safetensors 一个文件搞定,而不是每个 param 一段碎数据。
4.2.5 在原生 load_weights 上做 NaN-masked overwrite
_apply_delta_payload 的核心循环:
with _delta_apply_context(self.model):
chunk = [] # list[(name, tensor)]
chunk_bytes = 0
for param in params:
tensor = self._decode_delta_one_param(...) # 全 shape NaN tensor
if chunk and chunk_bytes + size > chunk_byte_cap: # 512MB cap
self.model.load_weights(chunk) # ← 原生 loader
chunk = []; chunk_bytes = 0
chunk.append((param.name, tensor))
chunk_bytes += size
if chunk:
self.model.load_weights(chunk)
几点:
chunk是list[(str, torch.Tensor)],不是 torch param——它是 SGLangmodel.load_weights(weights: Iterable[(name, tensor)])这个接口期望的「权重流」。name就是DeltaParam.name(HF 名字,从 sender 端 manifest 透传过来)。- 接口只要两个东西:HF 名字 + 全 shape 源张量。每个模型的
load_weights内部自己负责 HF→内部参数名映射、QKV split/fuse、quantize 等,最终一定落到tensor.copy_(src)写 GPU 权重——这是下一节 monkeypatch 拦截的关键点。 - chunk_byte_cap 控的是接收端 VRAM 峰值,和发送端 bucket size 是两层独立 batching:sender bucket size =
--update-weight-buffer-size(控 wire 频率);receiver chunk size =--update-weight-delta-chunk-bytes(控 receiver VRAM 峰值)。互不相关。
4.2.6 _delta_apply_context:临时 monkeypatch copy_ / fill_
这是整套接收端设计里最妙的一步。要把稀疏 delta 写回权重,直觉上得自己写一条「稀疏感知」的权重加载路径——可每个模型 family 的 load_weights 都不一样,还各自带着 fused QKV 拆分、量化、TP/PP 处理。这里的做法正相反:引擎原生的 load_weights 一行不改、完整复用,只在它最终会落到的 Tensor.copy_ / Tensor.fill_ 上 hook 一下,把「整张覆盖」换成「只覆盖非 NaN 的位置」。稀疏语义从最底层悄悄注入,上面那套 per-model 转换、量化、并行处理就全部原样拿来用了——接收端几乎没有重复实现任何模型相关的加载逻辑。
实现上,_delta_apply_context 是一个 contextmanager,进入时临时改写进程级的 torch.Tensor.copy_ 和 Tensor.fill_,退出时还原:
@contextlib.contextmanager
def _delta_apply_context(model):
is_param_target = _param_storage_index(model) # 见 §4.2.7
original_copy_, original_fill_ = Tensor.copy_, Tensor.fill_
def patched_copy_(self, src, *args, **kw):
if is_param_target(self) is not None: # 目标是模型权重?
mask = ~torch.isnan(src)
self[mask] = src[mask] # in-place 只写非 NaN 位置
return self
return original_copy_(self, src, *args, **kw) # 不是权重 → 原样
def patched_fill_(self, value):
if is_param_target(self) is not None and isnan(value):
return self # fill_(NaN) 到权重 → no-op
return original_fill_(self, value)
Tensor.copy_ = patched_copy_
Tensor.fill_ = patched_fill_
try: yield
finally: 复原
为什么 copy_ 要 patch:模型原生 load_weights 最后一定调 tensor.copy_(src)。如果不 patch,整张含 NaN 的 src 会直接覆盖到权重上,所有未变位置全变 NaN,模型报废。patch 后 copy_ 看 mask,只覆盖非 NaN 位置——in-place 直接写在已有 GPU 权重上,不新建权重张量。
为什么 fill_ 也要 patch(只拦 NaN 一种 case):copy_ 不是写权重的唯一通路。切片赋值 param[:] = scalar 底层、Tensor.zero_() 底层、PyTorch 内部某些 __setitem__ 都会走 fill_。只要其中任何一处出现 param.fill_(NaN),整张权重就被打成 NaN。但 patched_fill_ 只拦 NaN 一种情况——因为模型 loader 合法地会调 param.fill_(0)、zero_()、scale.fill_(1.0) 之类做初始化,把所有 fill_ 都 no-op 反而会破坏 loader。NaN 是 delta apply 的 sentinel,正常 load_weights 永远不会用 NaN 当 fill value,所以只拦 NaN 安全。
post_load_weights(fp8 scale / MoE bias 等后处理)会被包一层,在其中临时还原原生 copy_/fill_——这部分是纯算术后处理,不能被 mask 拦。这套设计保证:主 load_weights 阶段走 patched,后处理阶段走原生。
4.2.7 怎么认得「目标是模型权重」:_param_storage_index
patched_copy_ 里那一句 is_param_target(self) is not None 怎么实现?靠预先建一张 「GPU 内存地址区间 → owner param」 的查找表:
def _param_storage_index(model):
starts, ends, owners = [], [], []
for tensor in named_parameters() + named_buffers():
ptr = tensor.data_ptr() # GPU 内存指针(int)
starts.append(ptr); ends.append(ptr + tensor.nbytes)
owners.append(tensor)
# 按 start 排序,bisect 做 O(log n) 区间查找
def find_parent(dst):
idx = bisect.bisect_right(starts, dst.data_ptr()) - 1
if 0 <= idx and starts[idx] <= dst.data_ptr() < ends[idx]:
return owners[idx]
return None
return find_parent
关键性质:
data_ptr()是 GPU 设备指针(一个 int,如0x7f8c01a40000),不是 ordinal 索引。- slice / view 自动命中:PyTorch 的 view 只改 metadata,底层 storage 不变,
param[:, :half].data_ptr()自然落在父 param 的[start, end)区间内。不用手动枚举所有 view 形式。 - scratch buffer 自动排除:临时张量的指针落在 gap 里,不命中,走原生
copy_——不被 mask 干扰。 - 纯 CPU + O(log n):n 通常几百到几千,bisect 一次几百纳秒,相对
copy_的 kernel launch 可忽略。
4.2.8 为什么无损 + 无 drift
全程「按位覆盖、写入 trainer 的精确字节」,不做任何算术(不是 w += delta),因此天生 bit-identical,也不存在 additive delta 方案那种跨 step 的浮点累积漂移——所以不需要周期性 full re-sync 来纠偏。这正是它与 additive 方案的根本区别。
4.2.9 已知缺陷:失败时 silent drift(THUDM/slime#2104)
apply 失败(checksum / 读盘 / decode 出错)时 receiver 只是 catch + log + 返回 (False, msg),而 sender 的 _finalize_sync 把这个返回值直接丢了。由于 sender 的 snapshot 在发送前就已推进,一旦某次 apply 静默失败,sender 就以为这些位置已经同步、之后不再 diff 出来,receiver 上这部分权重便永久 drift,直到重启重新 seed。NCCL 下要么成功要么整个 job 挂、基本触发不到;disk 跨 DC 时概率非零。我们开了 issue #2104 跟进,已有修复 PR #2119;verl 实现里我们直接在失败时触发一次 force full re-sync 补上。
4.3 改动的侵入性评估
- 对训练侧代码侵入很小:纯子类化加新增参数,不改动 loss、optimizer 及已有的 full-sync 路径,默认行为不变(全部集中在一个新文件里,独立于已有路径)。
- 但有一项实打实的资源开销:发送端那份 pinned-CPU 全量快照,约等于在 host 内存里常驻一份完整模型;初始 seed 在 355B 上约 50s 阻塞。这是用「host 内存 + 一次性初始化」换「每步通信量」。
- 需要配套的引擎 build:接收端能力来自 SGLang 的 PR #26519,部署时用一个包含它的 SGLang build 即可(该 PR 进主分支前先自备一个)。
- 一处明确限制:
delta + colocate在 argparse 阶段即被拒绝。colocate 经由 CUDA IPC,进程间仅传递约 64 B 的内存 handle,delta 无字节可省,反而徒增 snapshot + diff + encode 的开销。
4.4 它与 RDMA 能否同时使用
可以,且二者正交。slime 将同步拆为两个独立的维度:
- 「发送什么」= mode:
full/delta - 「如何传输」= transport:
nccl/disk
| mode | transport | 行为 |
|---|---|---|
full |
nccl |
默认路径:将每个 HF 权重 chunk 经 trainer-engine NCCL group 广播 |
full |
disk |
写出完整 HF checkpoint,再由引擎 update_weights_from_disk 重载 |
delta |
nccl |
将稀疏的变化位置与值经 NCCL 广播 |
delta |
disk |
将稀疏 safetensors 写至共享 FS,再 push 给引擎 apply |
关键在于:
delta + nccl即 “delta over NCCL”。NCCL 底层同样运行在 IB / RoCE,即 RDMA fabric 之上——因此可同时获得 RDMA 的高带宽与仅传输约 1–3% 字节这两项收益,二者叠加而不冲突。slime 文档将 NCCL transport 定位为同数据中心内的验证基线,用于验证 wire 编码与 apply 逻辑的正确性。delta + disk(共享 FS / 对象存储) 则面向不具备 RDMA 的跨 DC / 跨 region 场景。此时 full broadcast 不可行,而稀疏 delta(355B 模型约 3% 密度,约 5GB)在数百 MB/s 的共享 FS 上是可接受的。
结论:delta 并非 RDMA 的替代品,而是在有 RDMA 时进一步减少传输字节、在无 RDMA 时使 RL 仍可解耦。
5. 小结
一个朴素的观察——RL 一个 step 之后大部分权重并未改变——在数月内改变了 RL 的成本结构:使 trainer 与 rollout 能够运行在普通网络乃至跨 region,tokens/$ 甚至可超过预留的 RDMA 集群(见 SparrowRL 的报告)。
几个值得继续探讨的开放问题:
- 更激进的有损 delta(例如舍弃极小的变化)能否在不影响收敛的前提下进一步压缩?
- 长时间训练中,若采用 additive 而非 overwrite,跨 step 的累积漂移边界如何界定?(slime 以纯 overwrite 回避了该问题。)
- 在 MoE 场景下,专家权重的稀疏性是否依然成立?不同专家被激活的频率差异是否会使 delta 分布不均?
这些可能是下一阶段工作的方向。
参考资料
- PULSE / PULSESync, arXiv 2602.03839
- SparrowRL(RL over Commodity Networks),arXiv 2602.11456
- SparseRL-Sync(Helix),arXiv 2605.07330
- Fireworks, “Frontier RL Is Cheaper Than You Think”
- Cursor, Composer 2 Technical Report
- Hugging Face TRL, “Shipping a Trillion Parameters With a Hub Bucket: Delta Weight Sync in TRL”
- slime, docs/en/advanced/delta-weight-sync.md
- vLLM #40096(sparse NCCL in-place,merged)、#44353(weight sync 重构)、issues #31848 / #39451
- Biao He, “Optimizing Weight Sync in slime”